Riepilogo della saga (e una confessione sul nome)
Negli articoli precedenti abbiamo raccontato come siamo passati da una singola VM con Docker Compose a un cluster Kubernetes su Talos OS, e come affrontiamo i backup su Kubernetes preservando lo stato dichiarativo invece di portarci dietro VM monolitiche da centinaia di GB.
In quell'articolo sui backup ho parlato di un tool che ci siamo dovuti scrivere perché nessuna soluzione, né commerciale né open source, faceva esattamente quello che ci serviva con la semplicità operativa che pretendevamo. Quel tool, internamente, ha un nome — KDR — e ammetto subito che è un nome provvisorio che ci portiamo dietro da mesi e che non abbiamo ancora avuto il coraggio di cambiare. Funziona così bene che il battesimo ufficiale slitta di sprint in sprint.
La cosa interessante è che KDR è nato per i backup, ma nel frattempo è cresciuto. È diventato lo strumento con cui guardiamo il cluster, non solo quello con cui lo mettiamo al sicuro. Questo articolo racconta come e perché.
Il pezzo che mancava: i log degli sviluppatori
Quando abbiamo migrato develop e staging su Kubernetes, abbiamo guadagnato un sacco di cose — parità con la produzione, autoscaling, fine dei container fantasma. Ma abbiamo anche scoperto un buco che con Docker Compose su una VM non sentivamo: lo sviluppatore non aveva più un modo semplice per leggere i log del proprio software una volta che girava in develop o staging.
Sulla vecchia VM, in fondo, bastava entrare e fare un docker logs. Su un cluster la storia è diversa: i pod stanno su nodi diversi, si ricreano, vengono schedulati altrove, e per leggere un log devi sapere kubectl, sapere in che namespace guardare, sapere come si chiama il pod giusto in quel preciso istante. Tradotto in pratica: lo sviluppatore apriva un messaggio a me o a chi gestiva il DevOps e chiedeva “mi mandi i log di staging di X?”. Moltiplicato per dieci persone e per le decine di volte al giorno in cui serve guardare un log mentre si lavora a una feature, è un collo di bottiglia assurdo. E un DevOps che fa da fotocopiatrice di log è un DevOps sprecato.
Grafana e Prometheus: motori ottimi, cruscotto da ingegneri
La prima risposta è stata quella ovvia, quella che fanno tutti: Grafana e Prometheus. Li abbiamo installati, configurati, collegati. E sotto il cofano funzionano benissimo — Prometheus come motore di metriche è uno standard de facto per ottime ragioni, e non abbiamo nessuna intenzione di buttarlo.
Il problema non è il motore. Il problema è il cruscotto.
Grafana è uno strumento progettato da programmatori per programmatori. È potentissimo, ma la sua UI/UX presuppone che tu sappia già cosa stai cercando, come si chiamano le metriche, come si scrive una query PromQL e come si costruisce una dashboard. Per chi ci vive dentro tutti i giorni è meraviglioso. Per uno sviluppatore frontend che vuole solo capire perché il suo servizio in staging risponde 500, è un muro. Ti ritrovi a spiegare alle persone come si usa lo strumento di osservabilità invece di farle osservare e basta.
E qui scatta la domanda da cui è partito tutto.
Le domande giuste (non solo i log)
Invece di accettare “Grafana è complicato, fattene una ragione”, mi sono chiesto due cose:
- Cosa posso fare per dare a tutti i log che gli servono, senza passare da me?
- Quali altri problemi hanno developer e DevOps — me compreso — con Grafana e, più in generale, con Kubernetes?
La seconda domanda è quella che ha trasformato un progetto piccolo in qualcosa di più ambizioso. Perché la verità è che il dolore non era solo “i log”. Era che il cluster è opaco. Per capire com'è messo un namespace, quante risorse ha, come sono configurati gli ingress, quale pod sta mangiando memoria e quale è in CrashLoopBackOff, devi mettere insieme tre o quattro strumenti diversi e un bel po' di comandi a memoria. Anche per noi che con kubectl ci litighiamo ogni giorno, è frizione.
Da queste due domande KDR si è esteso dall'essere un tool di backup a essere il nostro strumento di osservabilità del cluster.
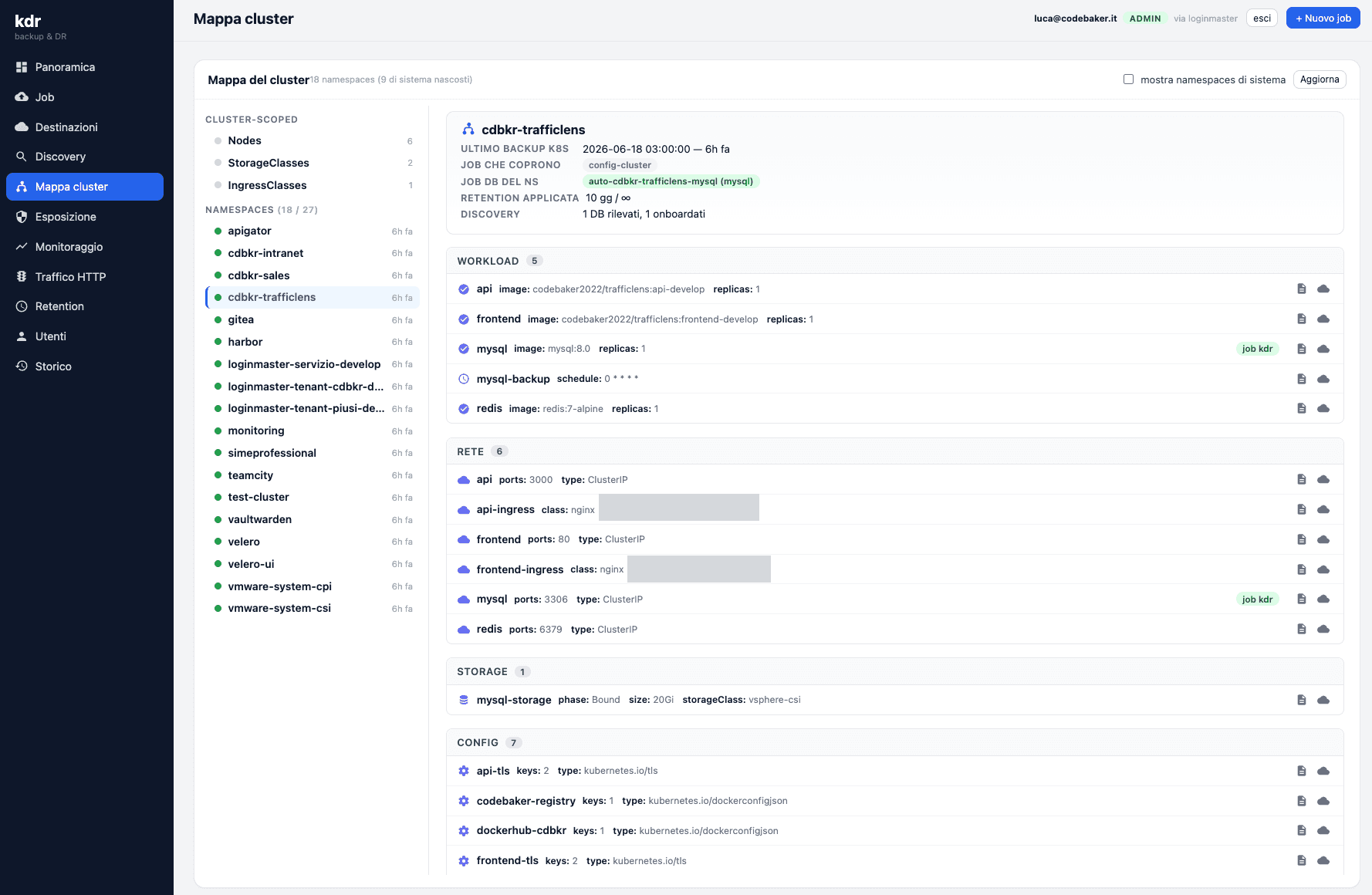
Cosa fa KDR oggi
Il design è la solita bussola che usiamo per ogni strumento interno: semplice, pulito, efficace. Niente cruscotti da configurare, niente PromQL da imparare. Apri, e vedi.
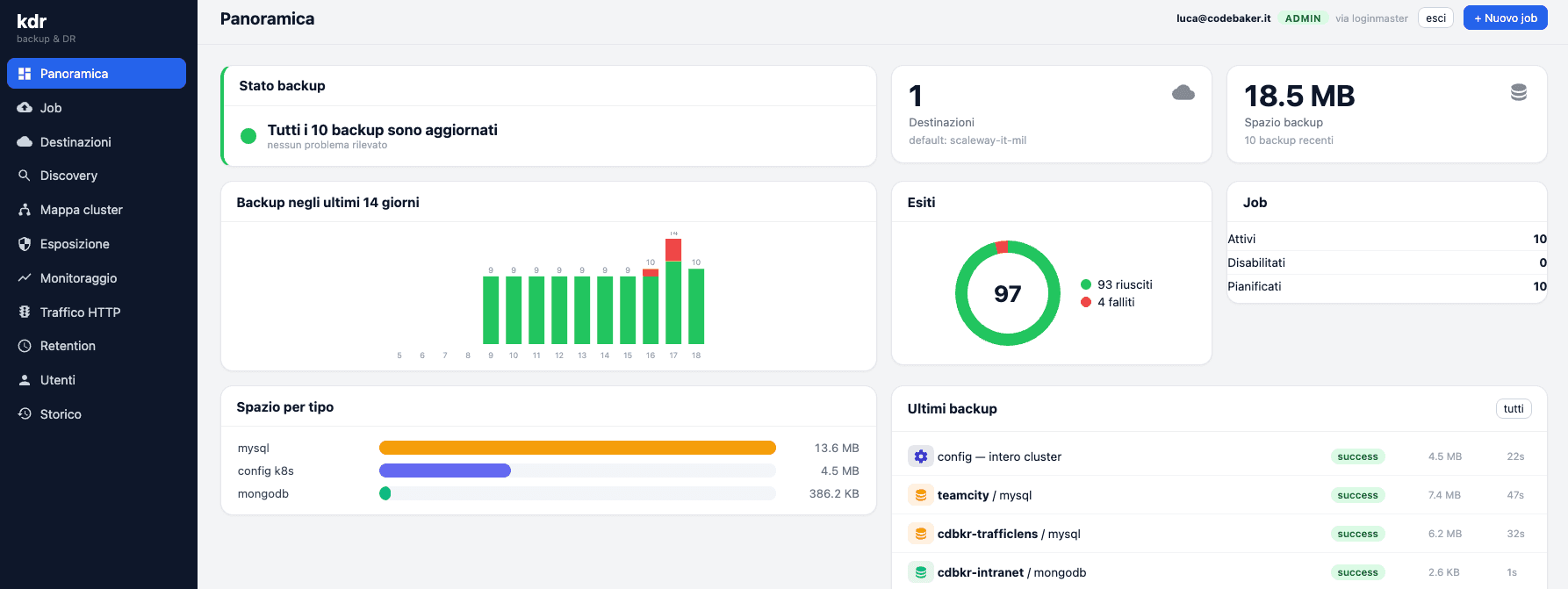
- Rappresenta graficamente la struttura del cluster. KDR disegna il cluster per quello che è: una gerarchia. Si parte dalla vista d'insieme e si scende — cluster → namespace → tipologia di risorsa → singolo pod — senza dover sapere in anticipo cosa cercare. È una mappa, non un terminale.
- Monitora ogni pezzo, dal cluster al singolo pod. Stato, salute, restart, consumo: a ogni livello vedi se le cose stanno girando come devono. Un pod in errore si nota subito, senza dover sapere che esiste.
- Suddivide le risorse per tipologia e per namespace. Deployment, Service, Ingress, ConfigMap, Secret, PVC raggruppati in modo leggibile, namespace per namespace. È la differenza tra “ho un elenco di 400 oggetti” e “ho una stanza ordinata in cui so dove guardare”.
- Rende leggibili le metriche di Prometheus. KDR intercetta le metriche che Prometheus già raccoglie e le presenta in modo comprensibile, senza chiedere all'utente di scrivere una query. Il motore resta Prometheus; sopra ci abbiamo messo un cruscotto pensato per gli esseri umani.
- Mostra ingress controller e configurazioni a colpo d'occhio. Capire come è instradato il traffico e come è configurato ogni singolo componente — senza fare l'archeologo tra
kubectl getekubectl describe— era uno dei dolori più sottovalutati. KDR te lo mette davanti.
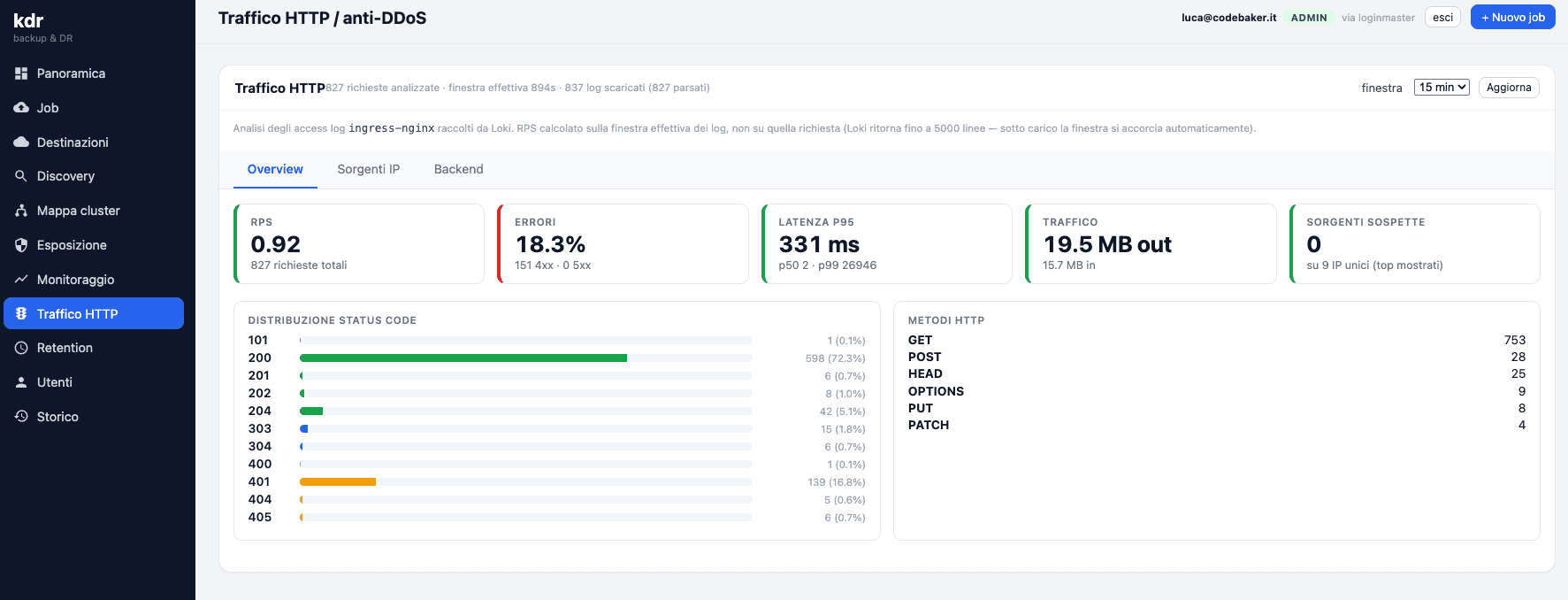
Il filo conduttore è uno solo: abbassare la barriera tra chi deve capire cosa sta facendo il cluster e il cluster stesso. Non perché Kubernetes vada nascosto, ma perché la maggior parte delle persone che ci lavorano sopra non deve diventare esperta di Kubernetes per fare il proprio mestiere.
I log, finalmente self-service
E veniamo al motivo per cui tutto è partito. Dentro KDR ogni sviluppatore ha il proprio accesso per analizzare i log dei servizi in develop e staging. In autonomia.
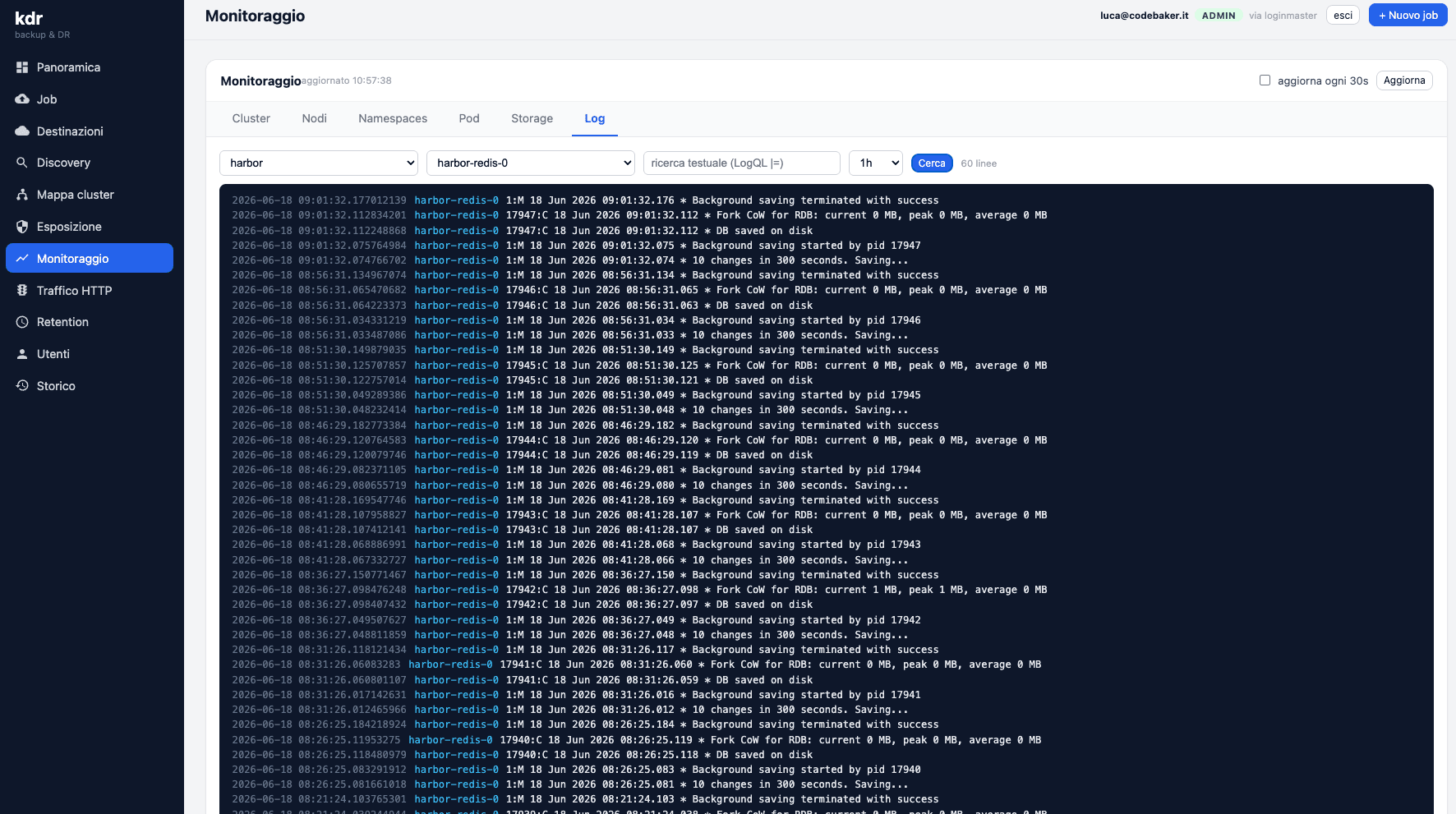
kubectlNiente più “mi mandi i log?”. Niente più DevOps che fa da intermediario tra lo sviluppatore e il suo stesso software. Lo sviluppatore apre KDR, trova il servizio, legge i log, capisce cosa è successo e torna a lavorare — il tutto senza un kubectl e senza disturbare nessuno.
Sembra una piccola cosa, ma cambia la dinamica del team in due modi. Primo: chi scrive il codice si riprende l'autonomia di debuggarlo, che è esattamente dove deve stare la responsabilità. Secondo: il reparto IT e il DevOps smettono di essere un servizio di consegna log e tornano a fare le cose per cui servono davvero. Tutti più contenti, me incluso.
Costruire invece di comprare (di nuovo)
Nell'articolo sui backup chiudevo con un consiglio: cercate strumenti che facciano quello che vi serve, e se non li trovate, scriveteli. KDR è la prova vivente di quella filosofia che cresce nel tempo. È nato per risolvere un problema (i backup), e proprio perché ce lo siamo scritti in casa, quando è emerso un problema adiacente (l'osservabilità) estenderlo è costato infinitamente meno che adottare, integrare e mantenere l'ennesimo prodotto di terze parti.
Non è una crociata contro l'open source o contro il commerciale — Prometheus lo usiamo e ce lo teniamo stretto. È una questione di dove mettere il confine: il motore lo prendiamo dove esiste già ed è ottimo, l'esperienza la costruiamo noi, su misura di come lavora davvero il nostro team. E lo facciamo restando su tecnologie e infrastrutture europee, perché la sovranità del dato per noi non è uno slogan da mettere in fondo a una slide.
Punti da portarsi a casa
Quattro cose, se anche voi avete un cluster e un team che ci deve lavorare sopra senza diventare tutti DevOps:
- 1
L'osservabilità non è “ho installato Grafana”. Il motore è metà del lavoro. L'altra metà è renderlo usabile da chi non vive dentro le query. Una UI pensata per gli ingegneri esclude tutti gli altri.
- 2
Date ai developer l'accesso autonomo ai propri log. Il DevOps che fa da fotocopiatrice di log è un collo di bottiglia e uno spreco. L'autonomia di debug va dove sta il codice.
- 3
Rendete il cluster leggibile, non solo interrogabile. Una mappa che scende dal cluster al pod, con risorse raggruppate per namespace e tipologia, vale più di mille comandi
kubectlimparati a memoria. - 4
Un buon tool interno cresce con voi. KDR è nato per i backup ed è diventato osservabilità. Quando lo strumento è vostro, estenderlo è naturale; quando è di qualcun altro, ogni nuova esigenza è una trattativa.
E sì, prima o poi gli daremo anche un nome serio.
Luca Vitali
Vuoi rendere leggibile il tuo cluster Kubernetes?
Codebaker progetta e gestisce infrastrutture Kubernetes su cloud europeo (Scaleway) e on-premise (vSphere + Talos OS), con osservabilità, backup e disaster recovery su misura. Se il tuo cluster è una scatola nera e vuoi cambiare le cose, parliamone.
Contattaci